Makefile学习笔记
本文最后更新于:2024年9月19日 晚上
0x00 引言
从前的我并不知道什么是make,这主要有两个原因,一是从前学习编程都是使用的都是windows平台,二是早期学习编程大都是单个文件实现一个简单的功能,不涉及到多文件编译,也用不到make。在windows平台,大多数项目有完备的IDE可以使用,像Visual Studio,MDK之类的,对于多文件的项目,它们都会有一个项目文件,通过项目文件打开该项目就能很容易的实现多文件编译。然而,随着学习的深入,越来越多的时候都在使用Linux开发,对于那些没有完备IDE支持的项目,学习如何自动化编译多文件项目就变得越来越重要。
其实,在这次下定决心学习Makefile之前,我其实也学习了Makefile几次,但是都浅尝辄止,半途而废了,仅仅只是学习了一些最最基础的语法,然而实际工作中,发现我学习的那些最基础的东西连项目给出的Makefile都读不懂,这次我决定一口气认认真真地学完Makefile,至少做到能看懂项目的Makefile,对于自己的一些小项目的Makefile要能够写出来。
学习Makefile,我选择的教材是我之前就学习过的陈皓大佬的《跟我一起写Makefile》。
其他资料:GNU make手册
0x01 什么是Makefile
-1- 编译过程
要了解Makefile首先要复习一下C文件的编译过程。这里要搬出一张经典的图片了。这里的预处理器,编译器,汇编器,连接器分别对应了不同的工具,这些工具共同组成了编译器。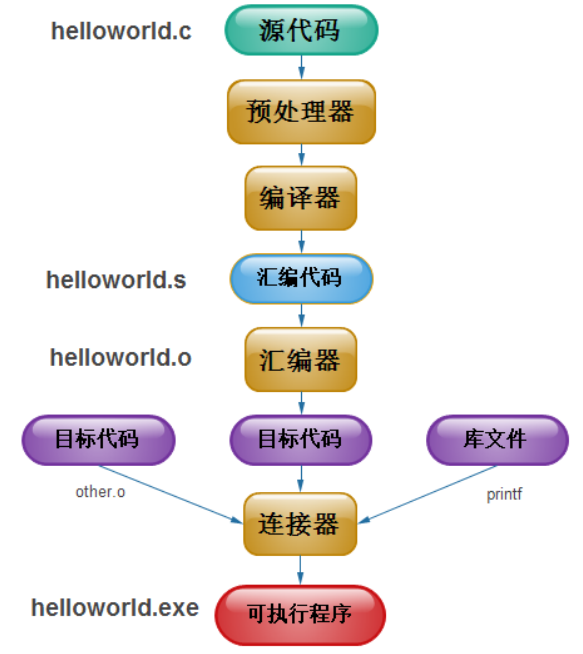
对于多文件项目,首先会将不同的源文件编译为目标文件,在Windows下也就是 .obj 文件,UNIX下是 .o 文件,即Object File。然后再将大量的目标文件连接在一起成为可执行文件,这个动作被叫做连接。
链接时,主要是链接函数和全局变量。所以,我们可以使用这些中间目标文件(
.o文件或.obj文件)来链接我们的应用程序。链接器并不管函数所在的源文件,只管函数的中间目标文件(Object File),在大多数时候,由于源文件太多,编译生成的中间目标文件太多,而在链接时需要明显地指出中间目标文件名,这对于编译很不方便。所以,我们要给中间目标文件打个包,在Windows下这种包叫“库文件”(Library File),也就是.lib文件,在UNIX下,是Archive File,也就是.a文件。
-2- make简介
make是Linux上最常用的项目管理工具,make命令可以帮助我们自动化完成上面提到的文件编译过程,并且帮助我们管理好源文件之间的依赖关系,当有源文件发生变化时,所有依赖于此源文件的源代码都会被重新编译。
make命令并不能凭空管理项目,它需要一个Makefile文件来描述项目中源文件的依赖关系,以及编译方法。所以学习使用make,就是学习如何编写Makefile。
makefile的文件名通常有三种格式:Makefile、makefile、GNUmakefile,make会在当前目录下自动寻找找三个文件名,如果没有找到的话,make就无法继续编译程序,产生一个错误并退出。
0x02 初识Makefile
-1- makefile基本规则
1 | |
target
可以是一个object file(目标文件),也可以是一个可执行文件,还可以是一个标签(label)。对于标签这种特性,在后续的“伪目标”章节中会有叙述。
prerequisites
生成该target所依赖的文件和/或target。
command
该target要执行的命令(任意的shell命令)。
这种格式描述了文件之间的依赖关系,也就是target依赖于prerequisites,且target这个文件的生成规则描述在recipe中。通俗来说就是:prerequisites中如果有一个以上的文件比target文件要新的话,command所定义的命令就会被执行。
一个示例
1 | |
关于CC与GCC
CC就是是C compiler,即C编译器,而GCC是GNU CC,也就是GNU C编译器,在linux中,cc实际上就是指向gcc,这是因为cc是Unix的软件,是要收费的,因此GNU组织就编写了免费开源的gcc来取代cc。
在这个makefile中,目标文件(target)包含:可执行文件edit和中间目标文件( *.o ),依赖文件(prerequisites)就是冒号后面的那些 .c 文件和 .h 文件。每一个 .o 文件都有一组依赖文件,而这些 .o 文件又是可执行文件 edit 的依赖文件。依赖关系的实质就是说明了目标文件是由哪些文件生成的,换言之,目标文件是哪些文件更新的。
以上的两个部分其实已经定义好了文件之间的依赖关系,但是在目标文件与依赖文件之间还缺少一个转化的桥梁,也就是我们还不知道如何将依赖文件转变为目标文件,所以其后的recipe就定义了如何将依赖文件变为目标文件的系统命令。但是值得注意的是,recipe中的命令完全是自定义的,make并不会去解读你的命令,它只会执行你所定义的命令。格式上,recipe一定要以指标符tab开头。
在给出的例子中,作为目标target的clean并不是一个文件,而是一个标签label,就和C语言中goto跳转的标签类似,它没有依赖文件,因此在执行make时不会自动执行,只有在显式的指出目标为clean时(make clean)才会执行其定义的recipe命令。借助这个特性,我们可以在makefile中定义很多非编译的但是能提高工作效率的命令,例如帮助我们清理构建文件 、程序打包、备份等等。
-2- make是如何工作的
在默认情况下,当我们在命令行中输入make时,make将会照如下的顺序执行
- make首先会在当前目录寻找
Makefile或者makefile - 如果找到,就会自动读取到第一个目标(这个目标可以是目标文件,也可以是label,make不做判断),这个目标就是make的最终目标,在前面的例子中,就是edit这个文件
- 如果edit这个文件不存在,或者是edit后面所依赖的文件(包括依赖文件的依赖文件)的修改时间要比edit更新,那么make就会自动执行command中所定义的命令来生成edit这个文件
- 如果edit的依赖文件中也有不存在的,或者不是最新的,那么make就会去寻找以该依赖文件为目标的规则,然后按照相同的过程去执行command命令生成这个依赖文件(就是一种递归)
- 最后edit的所有依赖文件都集齐了,就会执行edit对应的command命令,最后生成edit这个文件
在make的工作流程中,首先在读取最终目标时,make只会把一个target作为它的最终目标,只要此target规则中的依赖文件都集齐了,就会自动执行其后的shell命令,如果将clean的规则放在文件最开头,那么执行make也只会自动执行清除的命令,而后面的编译部分就全部不执行了。
其次,在检测依赖文件的修改时间时,要注意依赖文件的依赖也是当前目标文件的依赖,也是会检测的。举个例子,当已经执行了一次编译,此时所有的目标文件都已经生成了,然后修改其中的一个源文件files.c,然后执行make,按照执行流程,会选择edit作为最终目标,然后检测edit是否比它的依赖更新,files.c不是edit的依赖,但是却是files.o的依赖,而files.o是edit的依赖,因此files.c也可以视为edit的依赖,执行时会先重新生成files.o然后生成最终目标edit。
-3- makefile 中使用变量
在编写makefile时,特别是大型的makefile时,可能会遇到同一段字符串被反复使用,例如
1 | |
这里的依赖.o文件和后面command命令中所指明的.o文件都是一样的,当我们想要添加新的.o文件时,就需要在不同的地方手动添加,makefile足够大时,手动添加很难保证不出错,这极大地增加了makefile的维护成本。所以我们可以使用变量来代替原本的一连串.o文件,makefile中变量的本质类似于C语言中的宏定义,只做文本替换。我们用object来代替原本的一连串.o文件,原本的makefile就改进为
1 | |
-4- makefile 的自动推导机制
make可以自动推导出目标文件以及其依赖文件后面的命令,当make找到一个xxx.o文件,它就会自动把xxx.c加入到其依赖中,并且自动脑补出cc -c xxx.c的命令,因此,借助这个机制,makefile又可以被简化为
1 | |
这种书写方法属于make的隐式规则。.PHONY : clean表示clean是一个伪目标。
-5- 以源文件为中心的makefile风格
前面借助make的自动推导机制已经实现了省略了各.c文件,只留下了各自依赖的.h头文件,经过观察,可以发现这些不同的目标文件都依赖于几个相同的.h头文件。前面给出的makefile都是以不同的目标文件为中心编写的,其本质是列举出每个目标文件受哪些依赖文件的影响,那么是否可以反过来,以源文件(依赖文件)为中心,列举出不同源文件能影响哪些目标文件,答案自然是肯定的。新风格的makefile如下:
1 | |
defs.h会影响全部.o文件,command.h会影响kbd.o command.o files.o,buffer.h会影响display.o insert.o search.o files.o 。同时make的自动推导机制依然生效,每个.o文件依旧依赖于对应的.c文件。使用这种书写风格可以进一步简化makefile,同时也能表明文件之间的依赖关系。只不过采用这种风格会显得文件的依赖关系没那么清晰,需要阅读者在看的同时分析。
-6- 清空目录的规则
每个Makefile中都应该写一个清空目标文件( .o )和可执行文件的规则,这不仅便于重编译,也很利于保持文件的清洁。这是一个“修养”,通常的写法是
1 | |
而更为标准的写法应该是
1 | |
这里的.PHONY表明clean是一个伪目标。而在rm前面添加一个减号-表示当出现问题时,忽略错误,继续执行后面的内容。
clean 的规则不要放在文件的开头,不然,这就会变成make的默认目标,相信谁也不愿意这样。不成文的规矩是——“clean从来都是放在文件的最后”。
-7- makefile里有什么
Makefile里主要包含了五个东西:显式规则、隐式规则、变量定义、指令和注释。
- 显式规则。显式规则说明了如何生成一个或多个目标文件。这是由Makefile的书写者明显指出要生成的文件、文件的依赖文件和生成的命令。
- 隐式规则。由于我们的make有自动推导的功能,所以隐式规则可以让我们比较简略地书写Makefile,这是由make所支持的。
- 变量的定义。在Makefile中我们要定义一系列的变量,变量一般都是字符串,这个有点像你C语言中的宏,当Makefile被执行时,其中的变量都会被扩展到相应的引用位置上。
- 指令。其包括了三个部分:
- 一个是在一个Makefile中引用另一个Makefile,就像C语言中的include一样;
- 另一个是指根据某些情况指定Makefile中的有效部分,就像C语言中的预编译#if一样;
- 还有就是定义一个多行的命令。有关这一部分的内容,我会在后续的部分中讲述。
- 注释。Makefile中只有行注释,和UNIX的Shell脚本一样,其注释是用
#字符,这个就像C/C++中的//一样。如果你要在你的Makefile中使用#字符,可以用反斜杠进行转义,如:\#。
-8- Makefile文件名
默认的情况下,make命令会在当前目录下按顺序寻找文件名为 GNUmakefile 、 makefile 和 Makefile 的文件。在这三个文件名中,最好使用 Makefile 这个文件名,因为这个文件名在排序上靠近其它比较重要的文件,比如 README。最好不要用 GNUmakefile,因为这个文件名只能由GNU make ,其它版本的 make 无法识别,但是基本上来说,大多数的 make 都支持 makefile 和 Makefile 这两种默认文件名。
当然,也可以使用别的文件名来书写Makefile,比如:“Make.Solaris”,“Make.Linux”等,如果要指定特定的Makefile,你可以使用make的 -f 或 --file 参数,如: make -f Make.Solaris 或 make --file Make.Linux 。如果你使用多条 -f 或 --file 参数,可以指定多个makefile。
-9- 包含其他的Makefile
在Makefile使用 include 指令可以把别的Makefile包含进来,这很像C语言的 #include ,被包含的文件会原模原样的放在当前文件的包含位置。
1 | |
<filenames> 可以是当前操作系统Shell的文件模式(可以包含路径和通配符)。
在 include 前面可以有一些空字符,但是绝不能是 Tab 键开始。 include 和 <filenames> 可以用一个或多个空格隔开。举个例子,你有这样几个Makefile: a.mk 、 b.mk 、 c.mk ,还有一个文件叫 foo.make ,以及一个变量 $(bar) ,其包含了 bish 和 bash ,那么,下面的语句:
1 | |
等价于:
1 | |
make命令开始时,会找寻 include 所指出的其它Makefile,并把其内容安置在当前的位置。就好像C/C++的 #include 指令一样。如果文件都没有指定绝对路径或是相对路径的话,make会在当前目录下首先寻找,如果当前目录下没有找到,那么,make还会在下面的几个目录下找:
- 如果make执行时,有
-I或--include-dir参数,那么make就会在这个参数所指定的目录下去寻找。 - 接下来按顺序寻找目录
<prefix>/include(一般是/usr/local/bin)、/usr/gnu/include、/usr/local/include、/usr/include。
环境变量 .INCLUDE_DIRS 包含当前 make 会寻找的目录列表。你应当避免使用命令行参数 -I 来寻找以上这些默认目录,否则会使得 make “忘掉”所有已经设定的包含目录,包括默认目录。也就是说,使用了-I参数指定了include目录之后,make就只会在指定的目录下寻找,并且不再去默认的目录中寻找
如果有文件没有找到的话,make会生成一条警告信息,但不会马上出现致命错误。它会继续载入其它的文件,一旦完成makefile的读取,make会再重试这些没有找到,或是不能读取的文件,如果还是不行,make才会出现一条致命信息。如果你想让make不理那些无法读取的文件,而继续执行,你可以在include前加一个减号“-”。如:
1 | |
其表示,无论include过程中出现什么错误,都不要报错继续执行。如果要和其它版本 make 兼容,可以使用 sinclude 代替 -include 。
-10- 环境变量MAKEFILES
如果当前的环境中定义了MAKEFILES,那么make会把这个变量中的值作为一个类似于include的操作。这个变量的值是其他的makefile,用空格隔开。它与用include引入的其他makefile不同的是,从这个环境变量中引入的Makefile的“目标”不会起作用,如果环境变量中定义的文件发现错误,make也会不理。
使用这个环境变量会对所有的Makefile起作用,这显然是我们不希望看到的,因此不推荐使用这个环境变量
-11- make的工作方式
GNU的make工作时的执行步骤如下:(想来其它的make也是类似)
- 读入所有的Makefile。
- 读入被include的其它Makefile。
- 初始化文件中的变量。
- 推导隐式规则,并分析所有规则。
- 为所有的目标文件创建依赖关系链。
- 根据依赖关系,决定哪些目标要重新生成。
- 执行生成命令。
1-5步为第一个阶段,6-7为第二个阶段。第一个阶段中,如果定义的变量被使用了,那么,make会把其展开在使用的位置。但make并不会完全马上展开,make使用的是拖延战术,如果变量出现在依赖关系的规则中,那么仅当这条依赖被决定要使用了,变量才会在其内部展开。
0x03 书写规则
规则包含两个部分,一个是依赖关系,一个是生成目标的方法。
在Makefile中,规则的顺序是很重要的,因为,Makefile中只应该有一个最终目标,其它的目标都是被这个目标所连带出来的,所以一定要让make知道你的最终目标是什么。一般来说,定义在Makefile中的目标可能会有很多,但是第一条规则中的目标将被确立为最终的目标。如果第一条规则中的目标有很多个,那么,第一个目标会成为最终的目标。make所完成的也就是这个目标。
-1- 规则的语法
1 | |
或是这样:
1 | |
targets是文件名,以空格分开,可以使用通配符。一般来说,我们的目标基本上是一个文件,但也有可能是多个文件。
command是命令行,如果其不与“target:prerequisites”在一行,那么,必须以 Tab 键开头,如果和prerequisites在一行,那么可以用分号做为分隔。
prerequisites也就是目标所依赖的文件(或依赖目标)。如果其中的某个文件要比目标文件要新,那么,目标就被认为是“过时的”,被认为是需要重生成的。
如果命令太长,你可以使用反斜杠( \ )作为换行符。make对一行上有多少个字符没有限制。规则告诉make两件事,文件的依赖关系和如何生成目标文件。
一般来说,make会以UNIX的标准Shell,也就是 /bin/sh 来执行命令。
-2- 在规则中使用通配符
make支持三个通配符*,?和~。
*号代表任意个字符,这与正则表达式中的*号不同?号代表任意单个字符,但是此字符必须存在。这与正则表达式中的?号也不同~号代表home目录,在Unix环境下表示的就是当前用户的家目录路径,~hchen/test则表示用户hchen的宿主目录下的test 目录。在Windows的下视$HOME的环境变量定义而定。
这些通配符在变量中依然也是可以使用的,因为makefile的变量和宏定义一样,只做字符替换。
当然和正则表达式中的元字符一样,如果想要表示这些字符本身的意思,需要使用转义字符\来转义。
-3- 文件搜索
在大型工程中,通常有许许多多的源文件,为了管理这些源文件,通常会将其分类存放在不同的路径中,但是在描述文件依赖关系时,就需要带上这些目录路径,这会导致Makefile臃肿,且难以阅读。一个更好的解决方法是给出一个路径,让make自己去路径下寻找,而非总是指明文件的路径。
Makefile中的VPATH特殊变量就是用于完成这个功能的,在未定义此变量的情况下,Makefile默认只会在当前目录下寻找依赖文件和目标文件。而定义了VPATH变量之后,make就会在当前目录没有找到的情况下,继续去VPATH所定义的路径下继续寻找。这里给出一个例子
1 | |
上面的定义指定了两个目录,“src”和“../headers”,make会按照这个顺序进行搜索。目录由“冒号:”分隔。(当然,当前目录永远是最高优先搜索的地方)
另一个用于定义文件搜索路径的方法是使用关键字vpath(全小写),与前面提到的VPATH不同的是,vpath不是一个变量,而是一个make定义的关键字,它的使用方法更加灵活,它可以指定不同类型的文件在不同的路径下搜索。它主要有以下三种用法:
vpath <pattern> <directories>清除符合\<pattern\>模式的文件的搜索目录1
2
3
4
5
为符合\<pattern\>模式的文件指定搜索目录
* ```makefile
vpath <pattern>vpathvpath %.h ../headers1
2
3
4
5
6
7
清除所有设置好的文件的搜索目录
vpath使用方法中的\<pattern\>需要包含 `%` 字符。 `%` 的意思是匹配零或若干字符,(需引用 `%` ,使用 `\` )例如, `%.h` 表示所有以 `.h` 结尾的文件。\<pattern\>指定了要搜索的文件集,而\<directories\>则指定了\<pattern\>的文件集的搜索的目录。例如:1
2
3
4
5
6
7
8
9
10
11
该语句表示,要求make在“../headers”目录下搜索所有以 `.h` 结尾的文件。(如果某文件在当前目录没有找到的话)
---
可以连续地使用vpath语句,以指定不同搜索策略。如果连续的vpath语句中出现了相同的\<pattern\> ,或是被重复了的\<pattern\>,那么,make会按照vpath语句的先后顺序来执行搜索。如:
```makefile
vpath %.c foo
vpath % blish
vpath %.c bar
其表示 .c 结尾的文件,先在“foo”目录,然后是“blish”,最后是“bar”目录。
1 | |
而上面的语句则表示 .c 结尾的文件,先在“foo”目录,然后是“bar”目录,最后才是“blish”目录。
-4- 伪目标
前面有提到过,通常在makefile中会定义一个用于清除编译生成结果的目标clean,例如
1 | |
伪目标并不表示一个文件,它只是一个标签,就如同这里的clean一样,我们并不生成一个名为clean的文件。由于“伪目标”不是文件,所以make无法生成它的依赖关系和决定它是否要执行。我们只有通过显式地指明这个“目标”才能让其生效,也就是必须输入make clean才能执行后面定义的命令。伪目标不能和文件名同名,否则make就会错把伪目标当作一个文件,这样伪目标就失去意义了。
这里举个例子,如果能当前文件夹中存在一个名为clean的文件,此时执行make clean会发生什么呢?
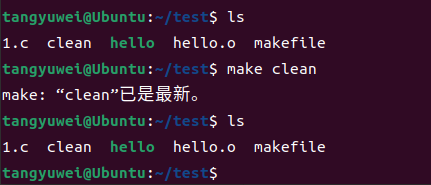
答案是什么都不会发生,因为make把clean当作了一个文件,而当前文件夹下已经存在了一个名为clean的文件,make就会认为它的任务已经完成了,输出了一个 make: “clean”已是最新 就退出了,这显然与我们设定的清除编译文件的目地不符。
那遇到这种情况我们难道除了修改伪目标名称之外就没有别的办法了吗?非也,我们可以显式的指定伪目标clean,这样的话,make就不会去管是否存在一个名为make的文件了,而是把clean当作一个完完全全的伪目标来对待
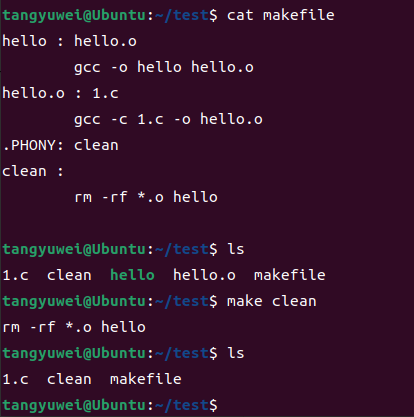
特殊的标记.PHONY用来显式地指明一个目标是“伪目标”,向make说明,不管是否有这个文件,这个目标就是“伪目标”。
1 | |
伪目标一般没有依赖的文件。但是,我们也可以为伪目标指定所依赖的文件。伪目标同样可以作为“最终目标”,只要将其放在第一个。一个示例就是,如果你的Makefile需要一口气生成若干个可执行文件,但你只想简单地敲一个make完事,并且,所有的目标文件都写在一个Makefile中,那么你可以使用“伪目标”这个特性:
1 | |
我们知道,Makefile中的第一个目标会被作为其默认目标。我们声明了一个“all”的伪目标,其依赖于其它三个目标。由于默认目标的特性是,总是被执行的,但由于“all”又是一个伪目标,伪目标只是一个标签不会生成文件,所以不会有“all”文件产生。于是,其它三个目标的规则总是会被决议。也就达到了我们一口气生成多个目标的目的。 .PHONY : all 声明了“all”这个目标为“伪目标”。(注:这里的显式“.PHONY : all” 不写的话一般情况也可以正确的执行,这样make可通过隐式规则推导出, “all” 是一个伪目标,执行make不会生成“all”文件,而执行后面的多个目标。建议:显式写出是一个好习惯。)
随便提一句,从上面的例子我们可以看出,目标也可以成为依赖。所以,伪目标同样也可成为依赖。看下面的例子:
1 | |
make cleanall将清除所有要被清除的文件。cleanobj和cleandiff这两个伪目标有点像“子程序”的意思。我们可以输入make cleanall 和 make cleanobj 和 make cleandiff命令来达到清除不同种类文件的目的。
-5- 多目标
Makefile的规则中的目标可以不止一个,其支持多目标,有可能我们的多个目标同时依赖于一个文件,并且其生成的命令大体类似。于是我们就能把其合并起来。当然,多个目标的生成规则的执行命令不是同一个,这可能会给我们带来麻烦,不过好在我们可以使用一个自动化变量 $@ (关于自动化变量,将在后面讲述),这个变量表示着目前规则中所有的目标的集合,这样说可能很抽象,还是看一个例子吧。
1 | |
上述规则等价于:
1 | |
其中, -$(subst output,,$@) 中的 $ 表示执行一个Makefile的函数,函数名为subst,后面的为参数。关于函数,将在后面讲述。这里的这个函数是替换字符串的意思, $@ 表示目标的集合,就像一个数组, $@ 依次取出目标,并执于命令。
-6- 静态模式
静态模式可以更加容易地定义多目标的规则,可以让我们的规则变得更加的有弹性和灵活。我们还是先来看一下语法:
1 | |
targets定义了一系列的目标文件,可以有通配符。是目标的一个集合。
target-pattern是指明了targets的模式,也就是的目标集模式。
prereq-patterns是目标的依赖模式,它对target-pattern形成的模式再进行一次依赖目标的定义。
这样描述这三个东西,可能还是没有说清楚,还是举个例子来说明一下吧。如果我们的<target-pattern>定义成 %.o ,意思是我们的<target>;集合中都是以 .o 结尾的,而如果我们的<prereq-patterns>定义成 %.c ,意思是对<target-pattern>所形成的目标集进行二次定义,其计算方法是,取<target-pattern>模式中的 % (也就是去掉了 .o 这个结尾),并为其加上 .c 这个结尾,形成的新集合。
所以,我们的“目标模式”或是“依赖模式”中都应该有 % 这个字符,如果你的文件名中有 % 那么你可以使用反斜杠 \ 进行转义,来标明真实的 % 字符。
看一个例子:
1 | |
上面的例子中,指明了我们的目标从$object中获取, %.o 表明要所有以 .o 结尾的目标,也就是 foo.o bar.o ,也就是变量 $object 集合的模式,而依赖模式 %.c 则取模式 %.o 的 % ,也就是 foo bar ,并为其加下 .c 的后缀,于是,我们的依赖目标就是 foo.c bar.c 。而命令中的 $< 和 $@ 则是自动化变量, $< 表示第一个依赖文件, $@ 表示目标集(也就是“foo.o bar.o”)。于是,上面的规则展开后等价于下面的规则:
1 | |
试想,如果我们的 %.o 有几百个,那么我们只要用这种很简单的“静态模式规则”就可以写完一堆规则,实在是太有效率了。“静态模式规则”的用法很灵活,如果用得好,那会是一个很强大的功能。再看一个例子:
1 | |
$(filter %.o,$(files))表示调用Makefile的filter函数,过滤“$files”集,只要其中模式为“%.o”的内容。其它的内容,我就不用多说了吧。这个例子展示了Makefile中更大的弹性。
-7- 自动生成依赖
在使用大型项目时,一个源文件通常会包含很多头文件,在编写Makefile时,人工手动维护这种依赖关系是一件很容易出错的事。而C/C++编译器提供的一项功能可以很好的解决这个问题。
1 | |
其输出是:
1 | |
编译器会自动生成的依赖关系,这样一来,就不必再手动书写若干文件的依赖关系,而由编译器自动生成了。需要提醒一句的是,如果使用GNU的C/C++编译器,你得用 -MM 参数,不然, -M 参数会把一些标准库的头文件也包含进来。
gcc -M main.c的输出是:
1 | |
gcc -MM main.c的输出则是:
1 | |
下面的问题是如何将此功能与Makefile结合起来呢,不可能让makefile本身也依赖于%.c,GNU组织建议把编译器为每一个源文件的自动生成的依赖关系放到一个文件中,为每一个 name.c 的文件都生成一个 name.d 的Makefile文件, .d 文件中就存放对应 .c 文件的依赖关系。
于是,我们可以写出 .c 文件和 .d 文件的依赖关系,并让make自动更新或生成 .d 文件,并把其包含在我们的主Makefile中,这样,我们就可以自动化地生成每个文件的依赖关系了。
这里,我们给出了一个模式规则来产生 .d 文件:
1 | |
这个规则的意思是,所有的 .d 文件依赖于 .c 文件, rm -f $@ 的意思是删除所有的目标,也就是 .d 文件,第二行的意思是,为每个依赖文件 $< ,也就是 .c 文件生成依赖文件, $@ 表示模式 %.d 文件,如果有一个C文件是name.c,那么 % 就是 name , $$$$ 意为一个随机编号,第二行生成的文件有可能是“name.d.12345”,第三行使用sed命令做了一个替换,也就是将name.c :替换为name.c name.d :。第四行就是删除临时文件。
这个模式要做的事就是在编译器生成的依赖关系中加入 .d 文件的依赖,即把依赖关系:
1 | |
转成:
1 | |
这样.d文件也会自动更新并且生成了
0x04 书写命令
每条规则中的命令和操作系统Shell的命令行是一致的。make会一按顺序一条一条的执行命令,每条命令的开头必须以 Tab 键开头,除非,命令是紧跟在依赖规则后面的分号后的。在命令行之间中的空格或是空行会被忽略,但是如果该空格或空行是以Tab键开头的,那么make会认为其是一个空命令。
我们在UNIX下可能会使用不同的Shell,但是make的命令默认是被 /bin/sh ——UNIX的标准Shell 解释执行的。除非你特别指定一个其它的Shell。Makefile中, # 是注释符,很像C/C++中的 // ,其后的本行字符都被注释。
-1- 显示命令
通常,make会把其要执行的命令行在命令执行前输出到屏幕上。当我们用 @ 字符在命令行前,那么,这个命令将不被make显示出来,最具代表性的例子是,我们用这个功能来向屏幕显示一些信息。如:
1 | |
当make执行时,会输出“正在编译XXX模块……”字串,但不会输出命令,如果没有“@”,那么,make将输出:
1 | |
如果make执行时,带入make参数 -n 或 --just-print ,那么其只是显示命令,但不会执行命令,这个功能很有利于我们调试我们的Makefile,看看我们书写的命令是执行起来是什么样子的或是什么顺序的。
而make参数 -s 或 --silent 或 --quiet 则是全面禁止命令的显示。
-2- 命令执行
如果需要让上一行的命令结果作用于下一行,就需要将这两个命令用分号隔开,而非将这两条命令放在两行。如:
- 示例一:
1 | |
- 示例二:
1 | |
当我们执行 make exec 时,第一个例子中的cd没有作用,pwd会打印出当前的Makefile目录,而第二个例子中,cd就起作用了,pwd会打印出“/home/hchen”。
-3- 命令出错
每当命令运行完后,make会检测每个命令的返回码,如果命令返回成功,那么make会执行下一条命令,当规则中所有的命令成功返回后,这个规则就算是成功完成了。如果一个规则中的某个命令出错了(命令退出码非零),那么make就会终止执行当前规则,这将有可能终止所有规则的执行。
有些时候,命令的出错并不表示就是错误的。例如mkdir命令,我们一定需要建立一个目录,如果目录不存在,那么mkdir就成功执行,万事大吉,如果目录存在,那么就出错了。我们之所以使用mkdir的意思就是一定要有这样的一个目录,于是我们就不希望mkdir出错而终止规则的运行。
为了做到这一点,忽略命令的出错,我们可以在Makefile的命令行前加一个减号 - (在Tab键之后),标记为不管命令出不出错都认为是成功的。如:
1 | |
如果在执行make时加上 -i 或是 --ignore-errors 参数,那么make将会被设定为全局忽略错误,也就是make会忽略掉makefile中全部的错误。
此外,和伪目标一样,我们可以用特殊标记.IGNORE将目标设定为忽略错误。例如
1 | |
这样,无论rm的执行正确与否,make都会忽略掉返回结果,认为是正确的。
还有一个要提一下的make的参数的是 -k 或是 --keep-going ,这个参数的意思是,如果某规则中的命令出错了,那么就终止该规则的执行,但继续执行其它规则。
-4- 嵌套执行make
在大型项目中,不同的功能、模块的源文件都被分类放在不同的文件夹目录下,如果将整个工程的编译规则都写在一个makefile中,会导致不便于维护,也会显得makefile过于臃肿,使用起来也不够灵活。为了解决这些问题,可以嵌套使用make,在每个模块的目录下都编写一个对应模块的makefile文件,将该模块下的编译规则、依赖信息写入对应的makefile下,然后在总的makefile中调用这些子目录下的makefile就能做到编译整个项目了。
例如,我们有一个子目录叫subdir,这个目录下有个Makefile文件,来指明了这个目录下文件的编译规则。那么我们总控的Makefile可以这样书写:
1 | |
其等价于:
1 | |
定义$(MAKE)宏变量的意思是,也许我们的make需要一些参数,所以定义成一个变量比较利于维护。这两个例子的意思都是先进入“subdir”目录,然后执行make命令。
总控Makefile的变量可以传递到下级的Makefile中(如果你显示的声明),但是不会覆盖下层的Makefile中所定义的变量,除非指定了 -e 参数。
如果你要传递变量到下级Makefile中,那么你可以使用这样的声明:
1 | |
如果你不想让某些变量传递到下级Makefile中,那么你可以这样声明:
1 | |
如果要传递所有的变量,那么,只要一个export就行了。后面什么也不用跟,表示传递所有的变量。
需要注意的是,有两个变量,一个是 SHELL ,一个是 MAKEFLAGS ,这两个变量不管你是否export,其总是要传递到下层 Makefile中,特别是 MAKEFLAGS 变量,其中包含了make的参数信息,如果我们执行“总控Makefile”时有make参数或是在上层 Makefile中定义了这个变量,那么 MAKEFLAGS 变量将会是这些参数,并会传递到下层Makefile中,这是一个系统级的环境变量。
但是make命令中的有几个参数并不往下传递,它们是 -C , -f , -h, -o 和 -W (-C 改变工作目录,-f 指定Makefile,-h 输出帮助信息,-o 指定文件不被更新,-W touch指定文件后执行),如果你不想往下层传递参数,那么,你可以这样来:
1 | |
还有一个在“嵌套执行”中比较有用的参数, -w 或是 --print-directory 会在make的过程中输出一些信息,让你看到目前的工作目录。比如,如果我们的下级make目录是“/home/hchen/gnu/make”,如果我们使用 make -w 来执行,那么当进入该目录时,我们会看到:
1 | |
而在完成下层make后离开目录时,我们会看到:
1 | |
当你使用 -C 参数来指定make下层Makefile时, -w 会被自动打开的。如果参数中有 -s ( --slient )或是 --no-print-directory ,那么, -w 总是失效的。
-5- 定义命令包
如果Makefile中出现一些相同命令序列,那么我们可以为这些相同的命令序列定义一个变量。定义这种命令序列的语法以 define 开始,以 endef 结束,如:
1 | |
这里,“run-yacc”是这个命令包的名字,其不要和Makefile中的变量重名。在 define 和 endef 中的两行就是命令序列。这个命令包中的第一个命令是运行Yacc程序,因为Yacc程序总是生成“y.tab.c”的文件,所以第二行的命令就是把这个文件改改名字。还是把这个命令包放到一个示例中来看看吧。
1 | |
我们可以看见,要使用这个命令包,我们就好像使用变量一样。在这个命令包的使用中,命令包“run-yacc”中的 $^ 就是 foo.y , $@ 就是 foo.c ,make在执行命令包时,命令包中的每个命令会被依次独立执行。
0x05 使用变量
这一部分,陈皓大佬写得有些冗杂,所以参考了makefile简明教程的部分。
Makefile中变量的本质有些类似于C语言中的宏定义,变量只做字符替换,在使用它的地方,变量会原封不动的展开。但是Makefile中的变量赋值使用比C语言的宏定义要更加灵活。在Makefile中,变量可以使用在“目标”,“依赖目标”, “命令”或是Makefile的其它部分中。
变量的命名字可以包含字符、数字,下划线(可以是数字开头),但不应该含有 : 、 # 、 = 或是空字符(空格、回车等)。变量是大小写敏感的,“foo”、“Foo”和“FOO”是三个不同的变量名。
此外,$< 、 $@ 等是自动化变量,可以帮助我们自动执行makefile规则,使makefile更加简洁。
-1- 变量的基础
变量在声明时需要给予初值,而在使用时,需要给在变量名前加上 $ 符号,但最好用小括号 () 或是大括号 {} 把变量给包括起来。如果要使用真实的 $ 字符,那么需要用 $$ 来表示。
变量可以使用在许多地方,如规则中的“目标”、“依赖”、“命令”以及新的变量中。
变量会在使用它的地方精确地展开,就像C/C++中的宏一样,例如:
1 | |
展开后得到:
1 | |
给变量加上括号,是为了更安全地使用变量,如果不加括号,其实也是可以使用的,但是可能会导致意料之外的情况,因此最好是在使用时加上变量。
-2- 变量的赋值
在Makefile中,给变量赋值一共有四种,分别代表不同的含义
=:延迟赋值:=:立即赋值+=:追加赋值?=:条件赋值
首先看前两种。在Makefile中,给一个变量A赋值时可以使用另外一个变量B的值。但是B变量的值在什么时候展开就区分了延迟赋值和立即赋值。看如下一个例子
1 | |
其结果为
1 | |
在这个例子中,val_a使用了立即变量,也就是在解析到该语句时,其后的$(a)就会立即解析出来为1,然后立即赋值给了val_a,也就相当于此时val_a的值已经锁定了。而val_b使用的是延迟变量,也就是$(b)的值在赋值时不会被解析,而是在使用时echo $(val_b)解析,此时的$(b)的值为20,所以此时val_b的值为20。
在make执行的过程中,在进入规则开始执行之前,make会先解析变量的值,确定一个最终值,这些都会发生在执行规则命令之前,这一点和宏定义很像,可以视作预编译的过程。
在make命令执行的过程中,变量值一般是不会更改的。在 Makefile 中,每个规则的执行都在一个子 Shell 中完成,这意味着在规则中对变量的更改不会影响到父 Shell 或其他规则。——来自ChatGPT
这两种赋值方式各有优劣,延迟赋值可以把变量的真实值推到后面来定义,但是可能造成嵌套定义的灾难;而立即赋值更接近C语言中宏定义的使用,遵循先定义后使用的规则,但是,在makefile中,使用未定义的变量来立即赋值不会报错,而是会直接忽视未定义的变量。例如:
1 | |
那么,y的值是bar,而不是foo bar。
再看后面两种赋值方式。追加赋值就是在原本的变量的基础上加上一部分,如:
1 | |
$(objects) 值变成:main.o foo.o bar.o utils.o another.o
如果变量之前没有定义过,那么, += 会自动变成 = ,如果前面有变量定义,那么 += 会继承于前次操作的赋值符。如果前一次的是 := ,那么 += 会以 := 作为其赋值符,如:
1 | |
等价于:
1 | |
还有一个赋值方式是条件赋值?=,它的含义是如果被赋值的变量之前未被赋值过,那么就将其赋值,如果被赋值变量此前已经被赋值过了,那就什么都不做。值得注意的时,条件赋值?=执行赋值时等价于延迟赋值=。
1 | |
其等价于:
1 | |
在变量赋值时要注意的是注释符
#的使用,#可以用来标识变量定义的终止
2nullstring :=
space := $(nullstring) # end of the linenullstring是一个Empty变量,其中什么也没有,而我们的space的值是一个空格。因为在操作符的右边是很难描述一个空格的,这里采用的技术很管用,先用一个Empty变量来标明变量的值开始了,而后面采用“#”注释符来表示变量定义的终止,这样,我们可以定义出其值是一个空格的变量。请注意这里关于“#”的使用,注释符“#”的这种特性值得我们注意,如果我们这样定义一个变量:
dir := /foo/bar # directory to put the frobs indir这个变量的值是“/foo/bar”,后面还跟了4个空格,如果我们这样使用这个变量来指定别的目录——“$(dir)/file”那么就完蛋了。
-3- 多行变量
使用define关键字可以定义多行变量,多行变量的值可以包含换行符,使用endef关键字标识多行变量定义的结束。若多行变量的值不是以TAB键开头,那么就不会被make认为是命令,所以前面的命令包的就是一种使用多行变量的例子。
多行变量的格式如下
1 | |
多行变量的赋值规则与=一样,也就是在使用此多行变量时才会展开
-4- override指令
如果有变量是由make命令行参数传入的,这些变量默认会屏蔽Makefile中的同名变量。如果要更改这些变量值,就需要使用override命令。其规则如下:
1 | |
对于多行变量的定义,同样可以使用override指令
1 | |
-5- 环境变量
make 运行时,系统的环境变量可以载入到Makefile文件中,但是如果该变量已经在Makefile中被定义了或是由make命令行参数引入了,那么系统的环境变量将会被屏蔽。(如果make指定了-e|--environment-overrides参数,那么,系统环境变量将覆盖Makefile中定义的变量)。Makefile中定义的变量和系统环境变量之间的关系 就类似于 局部变量和全局变量之间的关系
变量优先级:make命令行参数变量 > makefile自定义变量 > 系统环境变量
在make嵌套使用时,上层的Makefike中的自定义变量(用export指明的)会以系统环境变量的方式传入到下层的Makefile中。(默认情况下,只有make命令行参数变量会被传递)
-6- 变量替换
变量替换有两种模式,一种是替换指定字符串,另一种是模式替换。
第一种替换指定后缀字符串
先看如下的例子
1 | |
执行make命令,运行结果为:
1 | |
$(SRC:.c=.o)就实现了后缀字符串的替换,其含义为用.o替换掉原本的.c。所以,后缀字符串替换的规则格式如下
1 | |
值得注意的是,使用这种方法只能替换掉后缀字符串。
第二种模式替换
使用 % 保留变量值中的指定字符,替换其他字符。给出如下的例子
1 | |
执行make命令,运行结果为:
1 | |
-7- 自动化变量
在《跟我一起写Makefile》中,自动化变量的内容被放在了隐含变量-隐含规则链中,我这里就放在其他变量一起了。
自动化变量是为了简化编译命令而生的,对于那些使用模式规则编写的Makefile,使用自动化变量就能使用一个shell命令完成编译任务。举个例子:
1 | |
在这个示例中,模式规则设定了目标是所有以.o结尾的目标文件,而依赖是对应的.c源文件,对于这种模式规则,在编写命令时就需要使用到自动化变量来表示对应的目标和依赖了,其中$<表示的是依次取出的依赖文件,而$@表示依次取出的目标文件。
以下是常见的自动化变量的含义
$@: 表示规则中的目标文件集。在模式规则中,如果有多个目标,那么,$@就是匹配于目标中模式定义的集合。$%: 仅当目标是函数库文件中,表示规则中的目标成员名。例如,如果一个目标是foo.a(bar.o),那么,$%就是bar.o,$@就是foo.a。如果目标不是函数库文件(Unix下是.a,Windows下是.lib),那么,其值为空。$<: 依赖目标中的第一个目标名字。如果依赖目标是以模式(即%)定义的,那么$<将是符合模式的一系列的文件集。注意,其是一个一个取出来的。$?: 所有比目标新的依赖目标的集合。以空格分隔。$^: 所有的依赖目标的集合。以空格分隔。如果在依赖目标中有多个重复的,那么这个变量会去除重复的依赖目标,只保留一份。$+: 这个变量很像$^,也是所有依赖目标的集合。只是它不去除重复的依赖目标。$*: 这个变量表示目标模式中%及其之前的部分。如果目标是dir/a.foo.b,并且目标的模式是a.%.b,那么,$*的值就是dir/foo。这个变量对于构造有关联的文件名是比较有效。如果目标中没有模式的定义,那么$*也就不能被推导出,但是,如果目标文件的后缀是make所识别的,那么$*就是除了后缀的那一部分。例如:如果目标是foo.c,因为.c是make所能识别的后缀名,所以,$*的值就是foo。这个特性是GNU make的,很有可能不兼容于其它版本的make,所以,你应该尽量避免使用$*,除非是在隐含规则或是静态模式中。如果目标中的后缀是make所不能识别的,那么$*就是空值。
在上述所列出来的自动量变量中。四个变量( $@ 、 $< 、 $% 、 $* )在扩展时只会有一个文件,而另三个的值是一个文件列表。这七个自动化变量还可以取得文件的目录名或是在当前目录下的符合模式的文件名,只需要搭配上 D 或 F 字样。这是GNU make中老版本的特性,在新版本中,我们使用函数 dir 或 notdir 就可以做到了。 D 的含义就是Directory,就是目录, F 的含义就是File,就是文件。
下面是对于上面的七个变量分别加上 D 或是 F 的含义:
$(@D)表示
$@的目录部分(不以斜杠作为结尾),如果$@值是dir/foo.o,那么$(@D)就是dir,而如果$@中没有包含斜杠的话,其值就是.(当前目录)。$(@F)表示
$@的文件部分,如果$@值是dir/foo.o,那么$(@F)就是foo.o,$(@F)相当于函数$(notdir $@)。$(*D),$(*F)和上面所述的同理,也是取文件的目录部分和文件部分。对于上面的那个例子,
$(*D)返回dir,而$(*F)返回foo$(%D),$(%F)分别表示了函数包文件成员的目录部分和文件部分。这对于形同
archive(member)形式的目标中的member中包含了不同的目录很有用。$(<D),$(<F)分别表示依赖文件的目录部分和文件部分。
$(^D),$(^F)分别表示所有依赖文件的目录部分和文件部分。(无相同的)
$(+D),$(+F)分别表示所有依赖文件的目录部分和文件部分。(可以有相同的)
$(?D),$(?F)分别表示被更新的依赖文件的目录部分和文件部分。
-8- 目标变量
前面提过Makefile中自定义的变量与环境变量的关系类似于局部变量屏蔽全局变量的关系。那么,在Makefile文件中,是否还有更加局部的变量呢?答案是有的。我们知道在Makefile文件中定义的变量在整个文件中都可以使用,但是如果定义了目标变量,那么在此目标的规则中就可以使用同名的目标变量来屏蔽先前定义的全局变量了。
其语法是:
1 | |
<variable-assignment>可以是前面讲过的各种赋值表达式,如 = 、 := 、 += 或是 ?= 。第二个语法是针对于make命令行带入的变量,或是系统环境变量。
这个特性非常的有用,当我们设置了这样一个变量,这个变量会作用到由这个目标所引发的所有的规则中去。如:
1 | |
在这个示例中,不管全局的 $(CFLAGS) 的值是什么,在prog目标,以及其所引发的所有规则中(prog.o foo.o bar.o的规则), $(CFLAGS) 的值都是 -g
-9- 模式变量
在GNU的make中,还支持模式变量(Pattern-specific Variable),通过上面的目标变量中,我们知道,变量可以定义在某个目标上。模式变量的好处就是,我们可以给定一种“模式”,可以把变量定义在符合这种模式的所有目标上。
我们知道,make的“模式”一般是至少含有一个 % 的,所以,我们可以以如下方式给所有以 .o 结尾的目标定义目标变量:
1 | |
同样,模式变量的语法和“目标变量”一样:
1 | |
override同样是针对于系统环境传入的变量,或是make命令行指定的变量。
0x06 使用条件判断
使用条件判断,可以让make根据运行时的不同情况选择不同的执行分支。条件表达式可以是比较变量的值,或是比较变量和常量的值。在Makefile中,可以使用ifeq、ifneq、ifdef、ifndef 等关键字来进行条件判断。
先看一个例子:
1 | |
在这个示例中,根据$(CC)变量的值,会选择不同的库来完成编译。其中ifeq 、 else 和 endif是条件判断的关键字。 ifeq 的意思表示条件语句的开始,并指定一个条件表达式,表达式包含两个参数,以逗号分隔,表达式以圆括号括起。 else 表示条件表达式为假的情况。 endif 表示一个条件语句的结束,任何一个条件表达式都应该以 endif 结束。
当我们的变量 $(CC) 值是 gcc 时,目标 foo 的规则是:
1 | |
而当我们的变量 $(CC) 值不是 gcc 时(比如 cc ),目标 foo 的规则是:
1 | |
由此可以得出条件判断的语法规则:
1 | |
以及:
1 | |
其中 <conditional-directive> 表示条件关键字,一共有四个: ifeq、ifneq、ifdef、ifndef
-1- ifeq & ifneq
ifeq就是比较两个参数的值是否相等,如果相等则为真,否则为假。ifeq后面的参数有多种写法
1 | |
参数中还可以使用make的函数。如:
1 | |
这个示例中使用了 strip 函数,如果这个函数的返回值是空(Empty),那么 <text-if-empty> 就生效。
ifneq就是比较两个参数的值是否不相等,如果不相等则为真,否则为假。这就于ifeq刚好相反,不过多赘述。
-2- ifdef & ifndef
语法规则
1 | |
如果变量 <variable-name> 的值非空,那到表达式为真。否则,表达式为假。当然, <variable-name> 同样可以是一个函数的返回值。注意, ifdef 只是测试一个变量是否有值,其并不会把变量扩展到当前位置。还是来看两个例子:
示例一:
1 | |
示例二:
1 | |
第一个例子中, $(frobozz) 值是 yes ,第二个则是 no。
ifndef也是类似的,只是含义恰好相反,也不赘述了。
特别注意的是,make是在读取Makefile时就计算条件表达式的值,并根据条件表达式的值来选择语句,所以,最好不要把自动化变量(如 $@ 等)放入条件表达式中,因为自动化变量是在运行时才有的。
0x07 使用函数
在Makefile中可以使用函数来处理变量,从而让我们的命令或是规则更为的灵活和具有智能。make 所支持的函数也不算很多,不过已经足够我们的操作了。函数调用后,函数的返回值可以当做变量来使用。
-1- 函数的调用语法
函数调用,很像变量的使用,也是以 $ 来标识的,其语法如下:
1 | |
这里, <function> 就是函数名,make支持的函数不多。 <arguments> 为函数的参数,参数间以逗号 , 分隔,而函数名和参数之间以“空格”分隔。函数调用以 $ 开头,以圆括号或花括号把函数名和参数括起。
示例:
1 | |
在这个示例中, $(comma) 的值是一个逗号。 $(space) 使用了 $(empty) 定义了一个空格, $(foo) 的值是 a b c , $(bar) 的定义用,调用了函数 subst ,这是一个替换函数,这个函数有三个参数,第一个参数是被替换字串,第二个参数是替换字串,第三个参数是替换操作作用的字串。这个函数也就是把 $(foo) 中的空格替换成逗号,所以 $(bar) 的值是 a,b,c 。
-2- 字符串处理函数
subst
1 | |
名称:字符串替换函数
功能:把字串
<text>中的<from>字符串替换成<to>。返回:函数返回被替换过后的字符串。
示例:
1
$(subst ee,EE,feet on the street)
把 feet on the street 中的 ee 替换成 EE ,返回结果是 fEEt on the strEEt 。
patsubst
1 | |
名称:模式字符串替换函数。
功能:查找
<text>中的单词(单词以“空格”、“Tab”或“回车”“换行”分隔)是否符合模式<pattern>,如果匹配的话,则以<replacement>替换。这里,<pattern>可以包括通配符%,表示任意长度的字串。如果<replacement>中也包含%,那么,<replacement>中的这个%将是<pattern>中的那个%所代表的字串。(可以用\来转义,以\%来表示真实含义的%字符)返回:函数返回被替换过后的字符串。
示例:
1
$(patsubst %.c,%.o,x.c.c bar.c)
把字串 x.c.c bar.c 符合模式 %.c 的单词替换成 %.o ,返回结果是 x.c.o bar.o
strip
1 | |
名称:去空格函数。
功能:去掉
<string>字串中开头和结尾的空字符。返回:返回被去掉空格的字符串值。
示例:
1
$(strip a b c )把字串
a b c去掉开头和结尾的空格,结果是a b c。
findstring
1 | |
名称:查找字符串函数
功能:在字串
<in>中查找<find>字串。返回:如果找到,那么返回
<find>,否则返回空字符串。示例:
1
2$(findstring a,a b c)
$(findstring a,b c)
第一个函数返回 a 字符串,第二个返回空字符串
filter
1 | |
名称:过滤函数
功能:以
<pattern>模式过滤<text>字符串中的单词,保留符合模式<pattern>的单词。可以有多个模式。返回:返回符合模式
<pattern>的字串。示例:
1
2
3sources := foo.c bar.c baz.s ugh.h
foo: $(sources)
cc $(filter %.c %.s,$(sources)) -o foo$(filter %.c %.s,$(sources))返回的值是foo.c bar.c baz.s。
filter-out
1 | |
名称:反过滤函数
功能:以
<pattern>模式过滤<text>字符串中的单词,去除符合模式<pattern>的单词。可以有多个模式。返回:返回不符合模式
<pattern>的字串。示例:
1
2objects=main1.o foo.o main2.o bar.o
mains=main1.o main2.o$(filter-out $(mains),$(objects))返回值是foo.o bar.o。
sort
1 | |
- 名称:排序函数
- 功能:给字符串
<list>中的单词排序(升序)。 - 返回:返回排序后的字符串。
- 示例:
$(sort foo bar lose)返回bar foo lose。 - 备注:
sort函数会去掉<list>中相同的单词。
word
1 | |
- 名称:取单词函数
- 功能:取字符串
<text>中第<n>个单词。(从一开始) - 返回:返回字符串
<text>中第<n>个单词。如果<n>比<text>中的单词数要大,那么返回空字符串。 - 示例:
$(word 2, foo bar baz)返回值是bar。
wordlist
1 | |
- 名称:取单词串函数
- 功能:从字符串
<text>中取从<ss>开始到<e>的单词串。<ss>和<e>是一个数字。 - 返回:返回字符串
<text>中从<ss>到<e>的单词字串。如果<ss>比<text>中的单词数要大,那么返回空字符串。如果<e>大于<text>的单词数,那么返回从<ss>开始,到<text>结束的单词串。 - 示例:
$(wordlist 2, 3, foo bar baz)返回值是bar baz。
words
1 | |
- 名称:单词个数统计函数
- 功能:统计
<text>中字符串中的单词个数。 - 返回:返回
<text>中的单词数。 - 示例:
$(words, foo bar baz)返回值是3。 - 备注:如果我们要取
<text>中最后的一个单词,我们可以这样:$(word $(words <text>),<text>)。
firstword
1 | |
- 名称:首单词函数——firstword。
- 功能:取字符串
<text>中的第一个单词。 - 返回:返回字符串
<text>的第一个单词。 - 示例:
$(firstword foo bar)返回值是foo。 - 备注:这个函数可以用
word函数来实现:$(word 1,<text>)
以上,是所有的字符串操作函数,如果搭配混合使用,可以完成比较复杂的功能。这里,举一个现实中应用的例子。我们知道,make使用 VPATH 变量来指定“依赖文件”的搜索路径。于是,我们可以利用这个搜索路径来指定编译器对头文件的搜索路径参数 CFLAGS ,如:
1 | |
如果我们的 $(VPATH) 值是 src:../headers ,那么 $(patsubst %,-I%,$(subst :, ,$(VPATH))) 将返回 -Isrc -I../headers ,这正是cc或gcc搜索头文件路径的参数。
-3- 文件名操作函数
这些函数主要是处理文件名的。每个函数的参数字符串都会被当做一个或是一系列的文件名来对待。
dir
1 | |
- 名称:取目录函数——dir。
- 功能:从文件名序列
<names>中取出目录部分。目录部分是指最后一个反斜杠(/)之前的部分。如果没有反斜杠,那么返回./。 - 返回:返回文件名序列
<names>的目录部分。 - 示例:
$(dir src/foo.c hacks)返回值是src/ ./。
notdir
1 | |
- 名称:取文件函数——notdir。
- 功能:从文件名序列
<names>中取出非目录部分。非目录部分是指最後一个反斜杠(/)之后的部分。 - 返回:返回文件名序列
<names>的非目录部分。 - 示例:
$(notdir src/foo.c hacks)返回值是foo.c hacks。
suffix
1 | |
- 名称:取後缀函数——suffix。
- 功能:从文件名序列
<names>中取出各个文件名的后缀。 - 返回:返回文件名序列
<names>的后缀序列,如果文件没有后缀,则返回空字串。 - 示例:
$(suffix src/foo.c src-1.0/bar.c hacks)返回值是.c .c。
basename
1 | |
- 名称:取前缀函数——basename。
- 功能:从文件名序列
<names>中取出各个文件名的前缀部分。 - 返回:返回文件名序列
<names>的前缀序列,如果文件没有前缀,则返回空字串。 - 示例:
$(basename src/foo.c src-1.0/bar.c hacks)返回值是src/foo src-1.0/bar hacks。
addsuffix
1 | |
- 名称:加后缀函数——addsuffix。
- 功能:把后缀
<suffix>加到<names>中的每个单词后面。 - 返回:返回加过后缀的文件名序列。
- 示例:
$(addsuffix .c,foo bar)返回值是foo.c bar.c。
addprefix
1 | |
- 名称:加前缀函数——addprefix。
- 功能:把前缀
<prefix>加到<names>中的每个单词前面。 - 返回:返回加过前缀的文件名序列。
- 示例:
$(addprefix src/,foo bar)返回值是src/foo src/bar。
join
1 | |
- 名称:连接函数——join。
- 功能:把
<list2>中的单词对应地加到<list1>的单词后面。如果<list1>的单词个数要比<list2>的多,那么,<list1>中的多出来的单词将保持原样。如果<list2>的单词个数要比<list1>多,那么,<list2>多出来的单词将被复制到<list1>中。 - 返回:返回连接过后的字符串。
- 示例:
$(join aaa bbb , 111 222 333)返回值是aaa111 bbb222 333。
-4- foreach 函数
foreach是一个用于循环的函数,它的语法规则:
1 | |
这个函数的意思是,把参数 <list> 中的单词逐一取出放到参数 <var> 所指定的变量中,然后再执行 <text> 所包含的表达式。每一次 <text> 会返回一个字符串,循环过程中, <text> 的所返回的每个字符串会以空格分隔,最后当整个循环结束时, <text> 所返回的每个字符串所组成的整个字符串(以空格分隔)将会是foreach函数的返回值。
所以, <var> 最好是一个变量名, <list> 可以是一个表达式,而 <text> 中一般会使用 <var> 这个参数来依次枚举 <list> 中的单词。举个例子:
1 | |
上面的例子中, $(name) 中的单词会被挨个取出,并存到变量 n 中, $(n).o 每次根据 $(n) 计算出一个值,这些值以空格分隔,最后作为foreach函数的返回,所以, $(files) 的值是 a.o b.o c.o d.o 。
注意,foreach中的 <var> 参数是一个临时的局部变量,foreach函数执行完后,参数 <var> 的变量将不在作用,其作用域只在foreach函数当中。
-5- if函数
if函数很像GNU的make所支持的条件语句——ifeq(参见前面所述的章节),if函数的语法是:
1 | |
或是
1 | |
可见,if函数可以包含“else”部分,或是不含。即if函数的参数可以是两个,也可以是三个。 <condition> 参数是if的表达式,如果其返回的为非空字符串,那么这个表达式就相当于返回真,于是, <then-part> 会被计算,否则 <else-part> 会被计算。
而if函数的返回值是,如果 <condition> 为真(非空字符串),那个 <then-part> 会是整个函数的返回值,如果 <condition> 为假(空字符串),那么 <else-part> 会是整个函数的返回值,此时如果 <else-part> 没有被定义,那么,整个函数返回空字串。
所以, <then-part> 和 <else-part> 只会有一个被计算。
举个例子:
1 | |
在这个例子中,CFLAGS的值会更具DEBUG变量的值来选择,如果其值为1,则会选择-g -Wall,否则会选择-O2。
-6- call函数
call函数可以调用你自定义的参数化函数,你可以写一个非常复杂的表达式,这个表达式中,你可以定义许多参数,然后你可以call函数来向这个表达式传递参数。它的语法是:
1 | |
当执行这个函数时,会把参数 <parm1> 、 <parm2> 、 <parm3> 依次传入自定义的函数中的变量,最后的自定义函数返回值就是call函数的返回值。关于这个自定义函数,其变量通常用$(1) $(2) $(3)(以此类推)来表示传入的第1个、第2个、第3个参数。举个例子更好理解
1 | |
在这个例子中,concat就是一个我们自定义的简单函数,它接受两个参数$(1) 和$(2),并把它们按顺序连起来。所以最终如result的结果是HelloWorld
再举个例子
1 | |
此时的 foo 的值就是 b a 。
需要注意:在向 call 函数传递参数时要尤其注意空格的使用。call 函数在处理参数时,第2个及其之后的参数中的空格会被保留,因而可能造成一些奇怪的效果。因而在向call函数提供参数时,最安全的做法是去除所有多余的空格。
-7- origin函数
origin函数不像其它的函数,他并不操作变量的值,他只是告诉你你的这个变量是哪里来的?其语法是:
1 | |
注意, <variable> 是变量的名字,不应该是引用。所以你最好不要在 <variable> 中使用$ 字符。Origin函数会以其返回值来告诉你这个变量的“出生情况”,下面,是origin函数的返回值:
undefined如果
<variable>从来没有定义过,origin函数返回这个值undefineddefault如果
<variable>是一个默认的定义,比如“CC”这个变量,这种变量我们将在后面讲述。environment如果
<variable>是一个环境变量,并且当Makefile被执行时,-e参数没有被打开。file如果
<variable>这个变量被定义在Makefile中。command line如果
<variable>这个变量是被命令行定义的。override如果
<variable>是被override指示符重新定义的。automatic如果
<variable>是一个命令运行中的自动化变量。关于自动化变量将在前面介绍过了。
这些信息对于我们编写Makefile是非常有用的,例如,假设我们有一个Makefile其包了一个定义文件 Make.def,在 Make.def中定义了一个变量“bletch”,而我们的环境中也有一个环境变量“bletch”,此时,我们想判断一下,如果变量来源于环境,那么我们就把之重定义了,如果来源于Make.def或是命令行等非环境的,那么我们就不重新定义它。于是,在我们的Makefile中,我们可以这样写:
1 | |
当然,你也许会说,使用 override 关键字不就可以重新定义环境中的变量了吗?为什么需要使用这样的步骤?是的,我们用 override 是可以达到这样的效果,可是 override 过于粗暴,它同时会把从命令行定义的变量也覆盖了,而我们只想重新定义环境传来的,而不想重新定义命令行传来的。
-8- shell函数
shell函数就是用来执行shell命令的函数。它的参数是操作系统的shell命令,操作系统的标准输出会作为函数的返回值,可以用来给变量赋值,也可以用于函数的嵌套。
1 | |
除了shell函数之外,直接在shell命令前后加上反引号`,这样同样也能执行shell命令。
1 | |
注意,这个函数会新生成一个Shell程序来执行命令,所以你要注意其运行性能,如果你的Makefile中有一些比较复杂的规则,并大量使用了这个函数,那么对于你的系统性能是有害的。特别是Makefile的隐式规则可能会让你的shell函数执行的次数比你想像的多得多。
-9- 控制make函数
make提供了一些函数来控制make的运行。通常,你需要检测一些运行Makefile时的运行时信息,并且根据这些信息来决定,你是让make继续执行,还是停止。
1 | |
产生一个致命的错误, <text ...> 是错误信息。注意,error函数不会在一被使用就会产生错误信息,所以如果你把其定义在某个变量中,并在后续的脚本中使用这个变量,那么也是可以的。例如:
示例一:
1 | |
示例二:
1 | |
示例一会在变量ERROR_001定义了后执行时产生error调用,而示例二则在目录err被执行时才发生error调用。
1 | |
这个函数很像error函数,只是它并不会让make退出,只是输出一段警告信息,而make继续执行。
0x08 Make的运行
这一部分主要是make这个命令是如何使用的,以及make有关参数的讲解。
-1- make的退出码
make命令执行后有三个退出码:
0
表示成功执行。
1
如果make运行时出现任何错误,其返回1。
2
如果你使用了make的“-q”选项,并且make使得一些目标不需要更新,那么返回2。
-2- 指定Makefile
GNU make找寻默认的Makefile的规则是在当前目录下依次找三个文件——“GNUmakefile”、“makefile”和“Makefile”。其按顺序找这三个文件,一旦找到,就开始读取这个文件并执行。
如果希望make执行我们指定的makefile,那么可以使用make的 -f 或是 --file 参数( --makefile 参数也行)。例如,我们有个makefile的名字是“hchen.mk”,那么,我们可以这样来让make来执行这个文件:
1 | |
如果在make的命令行不只一次地使用了 -f 参数,那么,所有指定的makefile将会被连在一起传递给make执行。
-3- 指定目标
一般来说,make的最终目标是makefile中的第一个目标,而其它目标一般是由这个目标连带出来的。这是make的默认行为。如果希望make以我们指定的目标为最终目标的话,就可以显式的指出你希望完成的目标,类似于make clean。
任何在makefile中的目标都可以被指定成终极目标,但是除了以 - 打头,或是包含了 = 的目标,因为有这些字符的目标,会被解析成命令行参数或是变量。甚至没有被我们明确写出来的目标也可以成为make的终极目标,也就是说,只要make可以找到其隐含规则推导规则,那么这个隐含目标同样可以被指定成终极目标。
有一个make的环境变量叫 MAKECMDGOALS ,这个变量中会存放你所指定的终极目标的列表,如果在命令行上,你没有指定目标,那么,这个变量是空值。这个变量可以让你使用在一些比较特殊的情形下。比如下面的例子:
1 | |
基于上面的这个例子,只要我们输入的命令不是“make clean”,那么makefile会自动包含“foo.d”和“bar.d”这两个makefile。
使用指定终极目标的方法可以很方便地让我们编译我们的程序,例如下面这个例子:
1 | |
从这个例子中,我们可以看到,这个makefile中有四个需要编译的程序——“prog1”, “prog2”,“prog3”和 “prog4”,我们可以使用“make all”命令来编译所有的目标(如果把all置成第一个目标,那么只需执行“make”),我们也可以使用 “make prog2”来单独编译目标“prog2”。
即然make可以指定所有makefile中的目标,那么也包括“伪目标”,于是我们可以根据这种性质来让我们的makefile根据指定的不同的目标来完成不同的事。在Unix世界中,软件发布时,特别是GNU这种开源软件的发布时,其makefile都包含了编译、安装、打包等功能。我们可以参照这种规则来书写我们的makefile中的目标。
- all:这个伪目标是所有目标的目标,其功能一般是编译所有的目标。
- clean:这个伪目标功能是删除所有被make创建的文件。
- install:这个伪目标功能是安装已编译好的程序,其实就是把目标执行文件拷贝到指定的目标中去。
- print:这个伪目标的功能是例出改变过的源文件。
- tar:这个伪目标功能是把源程序打包备份。也就是一个tar文件。
- dist:这个伪目标功能是创建一个压缩文件,一般是把tar文件压成Z文件。或是gz文件。
- TAGS:这个伪目标功能是更新所有的目标,以备完整地重编译使用。
- check和test:这两个伪目标一般用来测试makefile的流程。
-2- 检查规则
有时候,我们不想让我们的makefile中的规则执行起来,我们只想检查一下我们的命令,或是执行的序列。于是我们可以使用make命令的下述参数:
-n,--just-print,--dry-run,--recon不执行参数,这些参数只是打印命令,不管目标是否更新,把规则和连带规则下的命令打印出来,但不执行,这些参数对于我们调试makefile很有用处。
-t,--touch这个参数的意思就是把目标文件的时间更新,但不更改目标文件。也就是说,make假装编译目标,但不是真正的编译目标,只是把目标变成已编译过的状态。
-q,--question这个参数的行为是找目标的意思,也就是说,如果目标存在,那么其什么也不会输出,当然也不会执行编译,如果目标不存在,其会打印出一条出错信息。
-W <file>,--what-if=<file>,--assume-new=<file>,--new-file=<file>这个参数需要指定一个文件。一般是是源文件(或依赖文件),Make会根据规则推导来运行依赖于这个文件的命令,一般来说,可以和“-n”参数一同使用,来查看这个依赖文件所发生的规则命令。
另外一个很有意思的用法是结合 -p 和 -v 来输出makefile被执行时的信息(这个将在后面讲述)。
-3- make参数
下面列举了所有GNU make 3.80版的参数定义。不过还是推荐去查看make的手册,这样可以得到最准确的解释。
-b,-m这两个参数的作用是忽略和其它版本make的兼容性。
-B,--always-make认为所有的目标都需要更新(重编译)。
-C, --directory=指定读取makefile的目录。如果有多个“-C”参数,make的解释是后面的路径以前面的作为相对路径,并以最后的目录作为被指定目录。如:“make -C ~hchen/test -C prog”等价于“make -C ~hchen/test/prog”。
-debug[=] 输出make的调试信息。它有几种不同的级别可供选择,如果没有参数,那就是输出最简单的调试信息。下面是
的取值:a: 也就是all,输出所有的调试信息。(会非常的多)b: 也就是basic,只输出简单的调试信息。即输出不需要重编译的目标。v: 也就是verbose,在b选项的级别之上。输出的信息包括哪个makefile被解析,不需要被重编译的依赖文件(或是依赖目标)等。i: 也就是implicit,输出所有的隐含规则。j: 也就是jobs,输出执行规则中命令的详细信息,如命令的PID、返回码等。m: 也就是makefile,输出make读取makefile,更新makefile,执行makefile的信息。 -d相当于“–debug=a”。
-e,--environment-overrides指明环境变量的值覆盖makefile中定义的变量的值。
-f=, --file=, --makefile=指定需要执行的makefile。
-h,--help显示帮助信息。
-i,--ignore-errors在执行时忽略所有的错误。
-I, --include-dir=指定一个被包含makefile的搜索目标。可以使用多个“-I”参数来指定多个目录。
-j[], --jobs[=] 指同时运行命令的个数。如果没有这个参数,make运行命令时能运行多少就运行多少。如果有一个以上的“-j”参数,那么仅最后一个“-j”才是有效的。(注意这个参数在MS-DOS中是无用的)
-k,--keep-going出错也不停止运行。如果生成一个目标失败了,那么依赖于其上的目标就不会被执行了。
-l, --load-average[=], -max-load[=] 指定make运行命令的负载。
-n,--just-print,--dry-run,--recon仅输出执行过程中的命令序列,但并不执行。
-o, --old-file=, --assume-old=不重新生成的指定的
,即使这个目标的依赖文件新于它。 -p,--print-data-base输出makefile中的所有数据,包括所有的规则和变量。这个参数会让一个简单的makefile都会输出一堆信息。如果你只是想输出信息而不想执行makefile,你可以使用“make -qp”命令。如果你想查看执行makefile前的预设变量和规则,你可以使用 “make –p –f /dev/null”。这个参数输出的信息会包含着你的makefile文件的文件名和行号,所以,用这个参数来调试你的 makefile会是很有用的,特别是当你的环境变量很复杂的时候。
-q,--question不运行命令,也不输出。仅仅是检查所指定的目标是否需要更新。如果是0则说明要更新,如果是2则说明有错误发生。
-r,--no-builtin-rules禁止make使用任何隐含规则。
-R,--no-builtin-variabes禁止make使用任何作用于变量上的隐含规则。
-s,--silent,--quiet在命令运行时不输出命令的输出。
-S,--no-keep-going,--stop取消“-k”选项的作用。因为有些时候,make的选项是从环境变量“MAKEFLAGS”中继承下来的。所以你可以在命令行中使用这个参数来让环境变量中的“-k”选项失效。
-t,--touch相当于UNIX的touch命令,只是把目标的修改日期变成最新的,也就是阻止生成目标的命令运行。
-v,--version输出make程序的版本、版权等关于make的信息。
-w,--print-directory输出运行makefile之前和之后的信息。这个参数对于跟踪嵌套式调用make时很有用。
--no-print-directory禁止“-w”选项。
-W, --what-if=, --new-file=, --assume-file=假定目标
;需要更新,如果和“-n”选项使用,那么这个参数会输出该目标更新时的运行动作。如果没有“-n”那么就像运行UNIX的“touch”命令一样,使得 ;的修改时间为当前时间。 --warn-undefined-variables只要make发现有未定义的变量,那么就输出警告信息。
附录
库文件相关问答
以下回答来自ChatGPT 3.5
Q:为什么目标要写成archive.a(member.o)这样
A:在GNU Make中,
archive.a(member.o)表示静态库(archive)中的一个成员(member),这种表示方式通常用于静态库的构建和维护。这里的archive.a是一个静态库文件,member.o是该静态库中的一个对象文件。这种语法的用途主要是对静态库进行精确的成员管理。你可以使用这种形式来指定只从静态库中提取或添加特定的对象文件,而不是整个静态库。
例如,在构建时,你可能只想要将某个对象文件加入静态库,而不是整个重新构建静态库。类似地,在一些规则中,你可能只关心特定的库成员。
语法为
archive.a(member.o)提供了精细的控制,使你能够指定与静态库关联的特定文件。这对于大型项目,特别是库的管理,非常有用。
Q:帮我解释一下库文件
A:库文件(Library)是一种包含可重用代码的二进制文件集合。这些文件包含已经编译好的对象代码,可以由程序员在其项目中引用,以便重用这些代码而不必重新编写。库文件的目的是提供一种模块化的方式来组织和共享代码。
有两种主要类型的库文件:
静态库(Static Library): 静态库是一组已编译的目标文件的集合,这些目标文件在链接时会被直接合并到最终的可执行文件中。它的文件扩展名通常是
.a(在Unix/Linux系统)或.lib(在Windows系统)。静态库的优点是在链接时会将库中的代码嵌入到可执行文件中,使得最终的可执行文件独立于库文件。缺点是如果多个程序使用相同的静态库,它们都会有一份该库的拷贝,可能导致可执行文件较大。
动态库(Dynamic Library): 动态库是一组已编译的目标文件的集合,它在运行时被加载到内存中,并可以被多个程序共享。它的文件扩展名通常是
.so(在Unix/Linux系统)或.dll(在Windows系统)。动态库的优点是多个程序可以共享同一份库,从而减小可执行文件的大小。缺点是程序在运行时需要确保动态库的存在,并且在不同的系统中可能需要处理不同的动态库版本和依赖关系。
在编写程序时,程序员可以通过链接器(Linker)将库文件与他们的代码链接起来。库文件中的代码可以包括函数、变量、类等,使得程序员可以使用这些库提供的功能而不必重新实现。库文件对于代码的组织和复用非常重要,它们提供了一种有效的方式来管理和共享代码。
Q:我可否理解成 库文件就是一类目标文件.o的集合
A:是的,你理解得很正确。库文件可以看作是一组目标文件(
.o文件)的集合。这些目标文件都是通过编译源代码而生成的,然后链接在一起形成一个库文件。库文件中的目标文件包含了已编译的代码,如函数、变量等,可以被其他程序或库引用。在静态库的情况下,这些目标文件在链接时会被直接合并到可执行文件中。在动态库的情况下,库文件在运行时被加载到内存中,并且多个程序可以共享同一份动态库。
因此,你可以将库文件视为一种组织和打包已编译代码的方式,以便于在不同的项目中进行共享和重用。
Q:在C语言中经常调用的printf函数是否已经编译为了库文件
A:是的,
printf函数通常包含在标准C库(Standard C Library)中,这是一个包含许多常见C语言函数的库。在大多数C编译器中,printf函数的实现是作为库的一部分提供的。对于大多数操作系统和编译器,C语言的标准库通常是由系统提供的。在Unix和Linux系统上,标准C库通常是
libc(例如,glibc是GNU C库的实现)。在Windows系统上,标准C库是 Microsoft C Runtime Library(CRT)。当你使用
printf函数时,编译器会知道在标准C库中查找这个函数的实现。在链接过程中,编译器会将标准C库链接到你的程序中,以确保printf等函数能够正确地被调用。在编写C程序时,你通常不需要显式链接标准C库,因为这通常是默认的。然而,在某些情况下,可能需要确保正确地链接了标准C库,特别是在一些嵌入式系统或裸机编程的场景中。
Q:那库文件的源文件为什么还存在呢
A:在软件开发中,库文件(静态库或动态库)的源文件通常是为了提供库的源代码,以便进行编译、调试、理解实现细节等目的。源文件通常以扩展名
.c(C语言源文件)或.cpp(C++语言源文件)为结尾。以下是为什么库文件的源文件仍然存在的一些原因:
调试和分析: 当开发者遇到问题时,有时需要查看库的源代码以进行调试和分析。源文件的可读性使得开发者能够理解库的实现细节,有助于定位和修复问题。
自定义编译: 有时,开发者可能希望使用不同的编译选项或对库进行一些修改,并重新编译库。在这种情况下,库的源文件是必需的。
构建特定版本: 在某些情况下,开发者可能需要构建特定版本的库,这可能需要访问库的源代码。
学习和教育: 学习和教育是另一个常见的原因。库的源代码可以作为学习编程、学习算法、学习库的实现方式的资源。
请注意,库的用户通常只需要库的二进制形式(静态库或动态库)以及相应的头文件(包含库的函数声明等),而不需要库的完整源代码。因此,发布库时,通常只提供二进制形式和头文件。然而,在开发阶段,库的源代码是非常重要的资源。
Q:在linux上,编译器如何根据头文件确定到对应的库文件呢,编译器如何区分是库文件的头文件还是用户自己编写的头文件呢
A:在Linux上,编译器(例如 GCC)如何找到对应的库文件与头文件有关。以下是一些关键的概念:
头文件(Header Files): 头文件通常具有
.h扩展名,包含了函数声明、结构体定义、常量等。头文件用于在源代码中声明函数或引入库的声明,以便编译器在编译时能够正确理解和验证对这些函数的调用。库文件(Library Files): 库文件通常包含已编译的二进制代码,例如静态库(
.a)或动态库(.so)。库文件提供了函数的实现,而头文件提供了函数的声明。搜索路径: 编译器使用一组搜索路径来查找头文件和库文件。这些路径包括系统默认路径和用户自定义路径。默认路径可能包括
/usr/include用于头文件,以及/usr/lib或/usr/lib64用于库文件。
头文件搜索路径: 编译器使用
-I选项指定额外的头文件搜索路径,例如-I/path/to/headers。库文件搜索路径: 编译器使用
-L选项指定额外的库文件搜索路径,例如-L/path/to/libs。库命名约定: 在Linux中,库文件的命名约定通常是
lib<name>.a或lib<name>.so,其中<name>是库的名字。例如,libm.a或libm.so。链接器选项: 在链接阶段,使用
-l选项指定要链接的库。例如,-lm表示链接数学库。链接器在搜索库文件时会根据命名约定自动查找合适的库文件。
静态库: 使用
-l<name>表示链接静态库。例如,-lmylib表示链接libmylib.a。动态库: 使用
-l<name>表示链接动态库。例如,-lmylib表示链接libmylib.so。在编译器搜索头文件和库文件时,它会按照特定的顺序和规则查找,通常按照用户指定的路径、系统默认路径以及一些标准路径。如果头文件或库文件在搜索路径中找不到,编译器将生成相应的错误信息。
对于区分库文件的头文件和用户自己编写的头文件,通常没有直接的方式。编译器根据搜索路径和命名约定来查找文件。如果头文件在系统默认路径或用户指定的路径中,并且符合命名约定,编译器就会找到它。因此,要确保头文件和库文件的名字不会与系统标准或其他库冲突。
Q:还是之前那个问题,编译器在预编译完成之后,以stdio.h为例,在编译printf这个函数时,编译器为什么知道该函数已经被编译为库函数了而非是.c的源码呢
A:当编译器在预处理和编译阶段处理源代码时,它会遇到
#include <stdio.h>这样的预处理指令。这个指令告诉编译器去系统的标准头文件路径中查找stdio.h文件并将其内容插入到源代码中。
stdio.h是标准C库头文件,其中包含了printf函数的声明。在预处理和编译阶段,编译器并不关心这个函数是如何实现的,它只需要知道函数的声明以便在后续阶段进行类型检查。在链接阶段,编译器会生成目标文件(
.o文件)包含了对printf函数的引用。然后,在链接器阶段,链接器会将目标文件与库文件链接在一起,以解析对printf的引用。如果是静态库,链接器会从静态库文件中提取
printf函数的实现,并将其嵌入最终的可执行文件中。如果是动态库,链接器会在运行时动态加载动态库,并将printf函数的地址解析为在库中的实现。在这个过程中,编译器并不关心
printf函数的具体实现是来自源代码还是库文件。它只关心函数的声明以及如何将对该函数的引用解析为实际的代码。这就是为什么在编译时,编译器并不需要源代码,而只需要头文件的原因。
Q:还是没懂,再详细解释一下
A:好的,让我更详细地解释一下整个过程。
预处理阶段:
- 在预处理阶段,编译器会执行一系列的预处理操作,其中之一是处理
#include指令。当编译器遇到#include <stdio.h>时,它会查找系统的标准头文件路径,找到stdio.h文件并将其内容插入源代码中。这是为了让编译器知道标准库中函数的声明,比如printf。编译阶段:
- 在编译阶段,编译器会将源代码翻译成汇编代码。这一阶段中,编译器只关注函数的声明,而不需要关心函数的实现。所以,在这个阶段,它并不需要
printf函数的源代码,只需要知道函数的声明,即函数的原型(prototype)。链接阶段:
- 在链接阶段,编译器生成目标文件(通常是
.o文件)。这个文件包含了对printf函数的引用,但并不包含函数的实现。- 接下来,链接器将目标文件与库文件链接在一起。对于
printf函数,它来自于标准C库(libc)。链接器会从标准C库中提取printf函数的实现,然后将其嵌入最终的可执行文件中。- 如果是静态库,整个
printf函数的实现将被嵌入到可执行文件中。- 如果是动态库,链接器会在可执行文件中留下一个引用,告诉操作系统在运行时需要动态加载
libc.so,并在内存中解析printf函数的地址。运行时阶段:
- 当你运行可执行文件时,操作系统会负责动态加载库(如果是动态库),并解析函数的地址。
- 在程序执行过程中,实际的
printf函数代码从库文件加载到内存中,并被调用。总结起来,编译器在编译阶段并不关心函数的具体实现,而是通过头文件获取函数的声明。在链接阶段,实际的函数实现会被链接到可执行文件中,无论是嵌入到可执行文件中(静态库)还是在运行时动态加载(动态库)。
Q:链接器将目标文件与库文件链接在一起。对于 printf 函数,它来自于标准C库(libc)。链接器会从标准C库中提取 printf 函数的实现,然后将其嵌入最终的可执行文件中。 在这个过程中,链接器为什么知道printf来自库文件而非其他的目标文件呢
A:在链接阶段,链接器并不是根据函数名直接知道一个函数是来自库文件还是其他目标文件。链接器主要通过符号解析(Symbol Resolution)的过程来确定符号(如函数名)的来源。这个过程包括以下几个步骤:
符号表(Symbol Table): 在目标文件和库文件中都包含有符号表,记录了文件中定义和引用的符号。符号可以是函数、变量或其他标识符。
符号解析: 链接器会遍历目标文件和库文件,查找每个文件中定义和引用的符号,并建立一个符号表的全局视图。
符号匹配: 当链接器遇到一个引用的符号(如
printf)时,它会在符号表中查找这个符号的定义。如果找到了,链接器就能确定这个符号是来自某个库文件或目标文件。库的搜索: 如果链接器在已知的目标文件中找不到符号的定义,它会继续搜索库文件。链接器会按照命令行参数的顺序搜索库,直到找到符号的定义或者遍历完所有的库。
在
printf的例子中,链接器首先在目标文件中查找printf的定义。如果找不到,它会继续搜索链接时指定的库文件,其中通常包括标准C库(libc)。关键点在于符号的定义和引用。如果目标文件或库文件中定义了
printf,链接器就能找到这个定义。如果没有,链接器就会在库文件中继续搜索。这是为什么在链接时需要指定库文件的原因,以便链接器知道从哪里找到缺失的符号。
Q:也就是说,即使我包含了stdio.h的头文件,但是我在某个.c中实现了printf的函数,那在链接时,printf最终就会指向我所编写的printf函数
A:是的,你理解得对。在链接阶段,链接器会根据符号解析的过程来确定最终引用的符号的实现。如果你在某个
.c文件中实现了printf函数,并且在其他文件中引用了printf,链接器会选择使用你自己实现的printf函数而不是标准C库中的版本。这种情况下,链接器会将你的
.c文件编译生成的目标文件(.o文件)与其他目标文件进行链接,生成最终的可执行文件。在这个过程中,符号解析确保所有引用的符号都能找到对应的定义。这也说明了为什么在C语言中,通常将函数的声明放在头文件中,而将函数的定义放在
.c文件中。头文件用于在编译阶段提供函数的声明,以便在其他文件中引用。然后,在链接阶段,链接器根据符号解析将这些引用与实际的定义连接起来。